In the Business world reports are inevitably driven by a data source. As soon as you assign a query to the report in the Pentaho Report Designer, Pentaho Reporting will invoke the query and shows you the columns of the query’s result. You then can drag-and-drop these fields into the report, select them from a drop-down for expressions or attributes that reference fields.
But as soon as you use any of the Advanced-DataSources, this comfort is gone. Advanced-DataSources do not have a valid query when designing the report. For these data-sources, the query text is computed when the report runs, using the parameter values and runtime information that is available at this time. At design time, this information is not available and thus there is no query to execute.
Luckily, there is a easy and simple way to solve this usability problem.
The key to the solution lays in the way the reporting engine evaluates calculated properties at runtime.
Calculations override static values
When the Pentaho report engine runs the report, calculations always override any design time value given. In the Pentaho Report Designer the design time value is specified in the column labelled “value”, while the calculated value is the result of evaluating the assigned formula or expression.

During design-time, while you are editing the report in the report designer, the editor only uses the specified “design-time-values”. It does not evaluate any of the assigned expressions.
As soon as you hit preview or if you execute the report on the Pentaho BI-platform on the server you enter the runtime mode. At this point, the reporting engine checks whether there is a expression assigned to the property and evaluates it. In that case, the expression’s calculated result is used and the design-time value is ignored. In case there is no expression defined, the reporting engine always uses the design-time value.
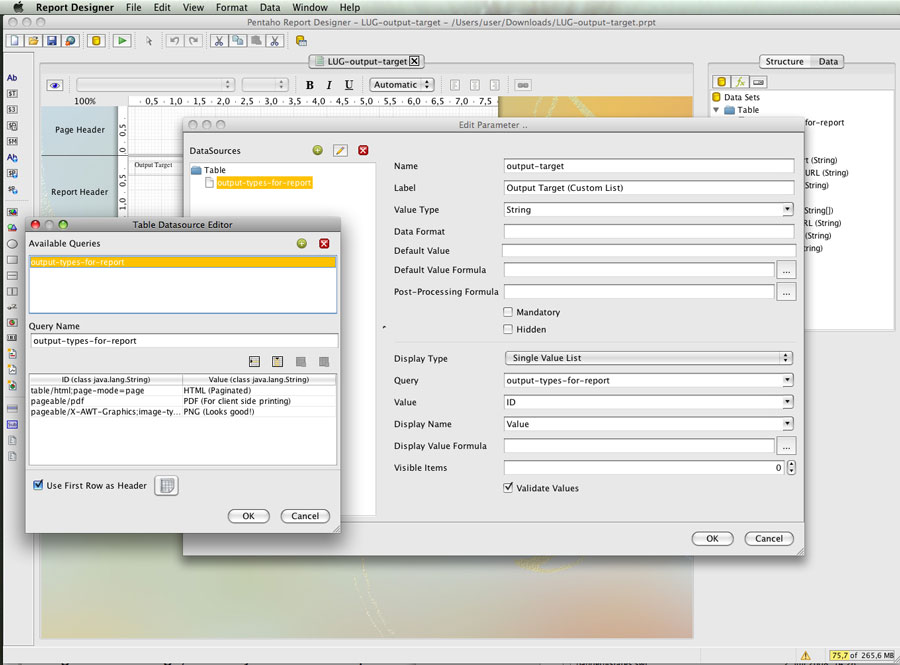
Armed with this knowledge, we can now provide a sensible design-time query as design-time value. To make this trick work properly, your static query must return the same columns as your calculated query will return.
How to avoid slow queries while designing the report
But what if your query is complex, expensive and just plain horrible to maintain or enter into the static value.
In this case you can make use of another property of the reporting engine. The Pentaho Reporting Engine has a well-defined way to find a suitable data source for the query at hand. Once the reporting engine has a query string, it will ask all ordinary data-sources, whether they can handle the query string given. This discovery is performed in the order the data sources have been defined on the report. Only if none of the ordinary data sources is able to handle the query at hand, the reporting engine asks the advanced data sources, whether they recognize the query.

Now, if you define a ordinary table-data-source, you can use this data-source as your design-time data-source by specifying the name of one of the defined queries in the “value” column of the report’s query attribute. As the reporting engine checks ordinary data sources first, the table-data-source will claim responsibility for this design-time query and will provide the result set for the design time. At runtime, the reporting engine will calculate the query string. The table-data-source will not recognized the query, and thus the Advanced DataDource can take its turn to execute the query and to return the runtime result set.
Avoid any database access at all while designing reports in the Report Designer
Last but not least: You can even use this trick to avoid any database access at all while being in design-mode.
For that trick to work, create both your runtime query using any data source you like. Additionally create a table-data-source with a table that mirrors your the structure of result set returned by the runtime data source. Make sure both data sources use different names for their recognized queries.
Now, on your report set the design-time value of the query attribute to the name of the table-data-source’s query. Set the formula to a formula that returns the runtime query.
="runtime-query"
Now, for design mode the report designer will hit the table-data-source and during preview or after publishing, you will automatically use the runtime data source.
With this knowledge, you should be able to work with Advanced-DataSources as comfortable as with any of the ordinary data sources.